常用 AI 工具推介
李二花 / 2024-03-26
现在市面上五花八门的 AI 工具都在强调自己很能打,但是到底哪些适合我们的工作生活呢?(时效性到 2024 年 3 月份)
从 23 年初到现在我也使用了非常多的此类工具了,在这里介绍几个在我的工作生活中扮演了十分重要角色的几个工具。 同时也简单介绍一些我觉得很有意思的可以形成一套工作流的工具。
准备工作
我要推荐的大部分的工具都是海外的产品,这些产品基本都会限制使用的 IP,因此为了能够正常的访问这些工具,需要你会科学上网。
之前也专门写过一些相关的内容,这次就做一个小的总结,然后把之前的一些链接也贴到这里,如果想要了解的话,可以看看。
![]()
| app | 功能 | 价格 | 地区 | 支持的系统 | 详情 |
|---|---|---|---|---|---|
| quantumulx-t | 流量分流 | $8 | 美区 | ios, macOS | 详情 |
| shadowrocket | 基本配置 | $3 | 美区 | ios, macOS | 十分简单,无需教程 |
| clash | 配置 + 分流 | free | 开源 | 无 ios | 详情 |
其中 clash 因为一些原因,已经删库了,目前只能去一些备份地址获取。
另外还有一些其他比较优秀的产品比如 surge, loon 等,但是对于我而言,这三个已经十分够用了。
当然这三个只是科学上网的工具,而具体的流量就需要你自己找方法了,有以下几种方案可以考虑:
- 购买现成的流量包:优点是各种国家地区的节点都有,缺点是贵和容易跑路
- 自己购买 VPS 搭建:优点是便宜可控,缺点是节点是固定的并且需要一定的 Linux 基础
- 使用赛博佛祖 Cloudflare 提供的 1.1.1.1: 赛博佛祖没有缺点(哈哈哈哈哈哈哈
我是这三种方案都在用,使用的是混合方案,流量包主要是用来走一些小众区域的流量的,比如土耳其和尼日利亚(同样的产品,土区和尼日利亚区价格会便宜很多,比如 spotify)。 自己购买搭建的主要用来走流量大的场景,比如看网飞的剧,刷 youtube 等,而 cloudflare 的一般是用来做兜底的,比如另外两个出了问题,我拿来应急用。
之前写的一篇关于 v2ray 的文章里面粗略的介绍了科学上网的原理,看这里.
关于赛博佛祖 Cloudflare 我之前的一些相关文章:
除了赛博佛祖外,还有赛博菩萨(supabase)和赛博罗汉(vercel), 都是个人用户必备神器。
工具介绍
会话类工具
chatgpt
这个是我一直在用的,一些脏活累活都交给他来做,比如:
- 写后端的一些工具代码
- 生成前端的一些页面模板(然后有时候很傻,需要我很多次的引导
- 以前需要查询 google 的一些知识类的,现在都是直接问
- 生成一些简单的,即时使用的图片(gpt4 的 DALLE-3)
- 帮我润色一些文字,让逻辑更清晰
- 赛博算命……
当然现在有了 kimi 之后,一些长文也会经常去问 kimi

poe
poe 是不是一个单纯的会话工具,是一个工具的集合平台,里面有各种各样的产品,包括 openai 的 chatgpt, 包括 claude 3, 包括一个其他大模型的工具。
我一般用这个平台是进行尝鲜,作为一个工具的集合,他是 OK 的,另外它便宜,gpt4 的会员版本是 $20 每月,而你使用相同的费用,可以购买到 poe 内集合的多种工具的会员权益。

kimi
kimi 是国内月之暗面出品的一款会话工具,目前依旧是免费的,上下文也比较长,支持联网和文档,我一般用来让他干一些更累的活,比如帮我处理 json 数据。
Ollama
Ollama 是一个本地运行模型的平台,你可以从平台下载任何你想运行的会话模型,然后跟他对话,除了可以在命令行运行外,有许多的 web-ui 可以跟 Ollama 交互。
Ollama 对机器的性能有一定的要求,小模型普通的 mac 机器可以跑起来,但是如果模型比较大,那普通的机器就跑不起来,需要专门的工作站了,不过可以放心的是,我已经试验过了 llama2 可以在 mac 上运行。
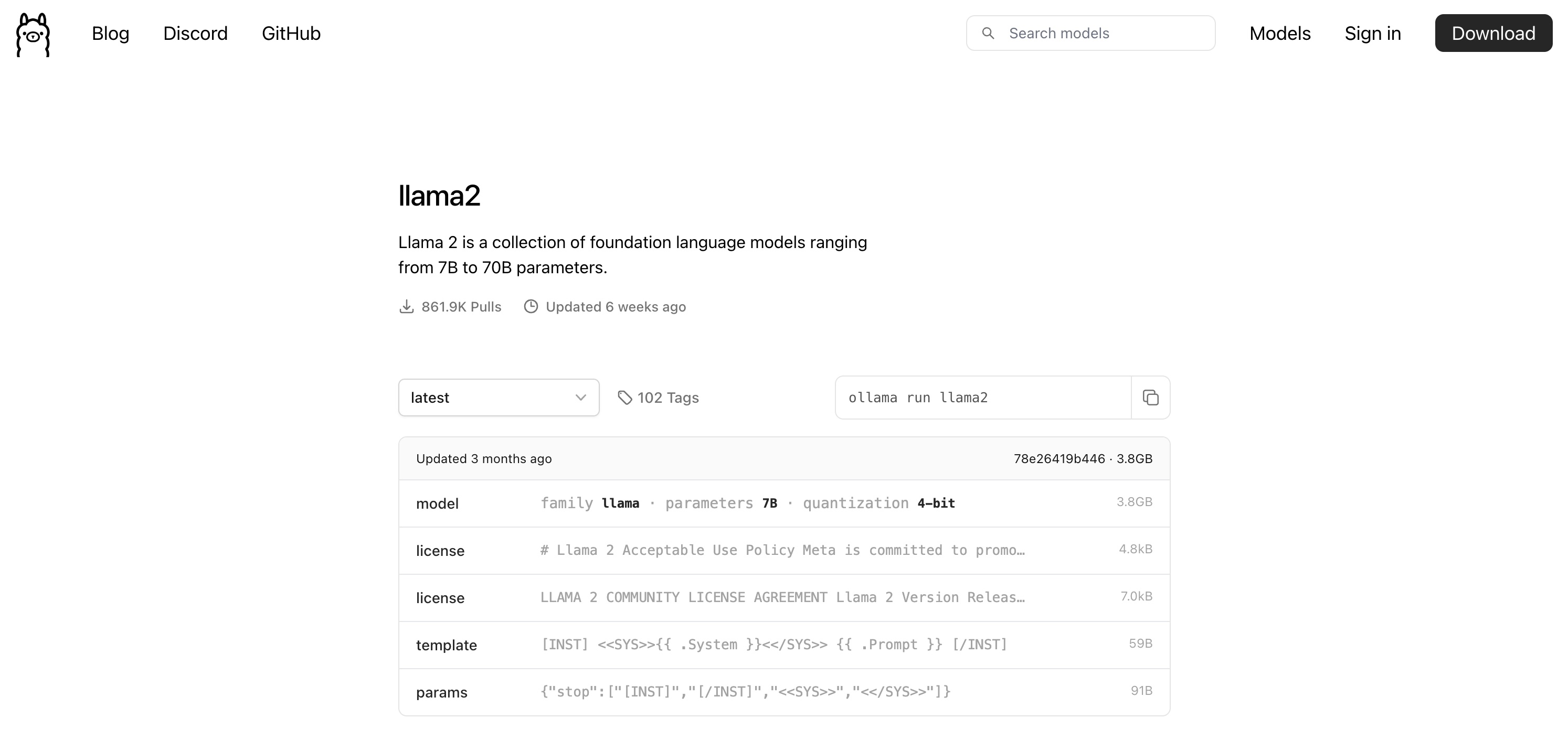
brew install ollama
ollama run llama2
翻译类工具
沉浸式翻译
是一款 chrome 插件,可以配置 openai key, gemini-pro key 来做页面的翻译,同时也支持普通的 google 翻译等,我一般用来做一些粗筛的工作时使用。
openai-translator
推友 yetone 开发的,支持 chrome 插件,支持各端的客户端版本,也是可以配置 openai key, gemini-pro key 等来做翻译工作,目前是我精读某些文章书籍时的必备产品。
比如最近在读的一本「THE PH.D. GRIND」就会用它来查一些学术方面的内容。
图片类工具
midjourney & 悠船
midjourney 以前是我使用的一个产品之一,每个月需要付费会员,但是后来发现了国内代理的悠船是免费的之后,开始用悠船,可以暂时认为这两者基本没有什么太大的差别。
悠船注册需要依托企业或者学校名义,我因为依旧保留着学校的邮箱,因此使用学校邮箱注册的。
这两款产品在生成的图片的质量和契合度上,感觉各有千秋, 也可能是我提示词写的不好,比不出来, 对比下两款产品生成的图片:
提示词: 欲买桂花同载酒,终不似,少年游

提示词: 夜雨秋灯

stable diffusion
相比于 midjourney 的开箱即用(付费用户),SD 的成本会高很多,但是精细化程度和可控程度要更高。
高成本体现在模型是跑在本地机器的,所以需要你有很好的显卡才能运行 SD,精细化是指除了 prompt 外,加上 lora, controlNet 等的加持,可以产出一些完全自己定制的图片。
stable diffusion 之前也写过几篇文章来介绍,同时,除了之前文章提到的部署方式,目前有了集成版本的,更加方便快捷。
集成版下载链接 提取码: 1026, 如遇过期,请左下角对话联系我。
同时对于 lora, controlNet 的介绍可以看这个文档,也可以直接问 GPT.
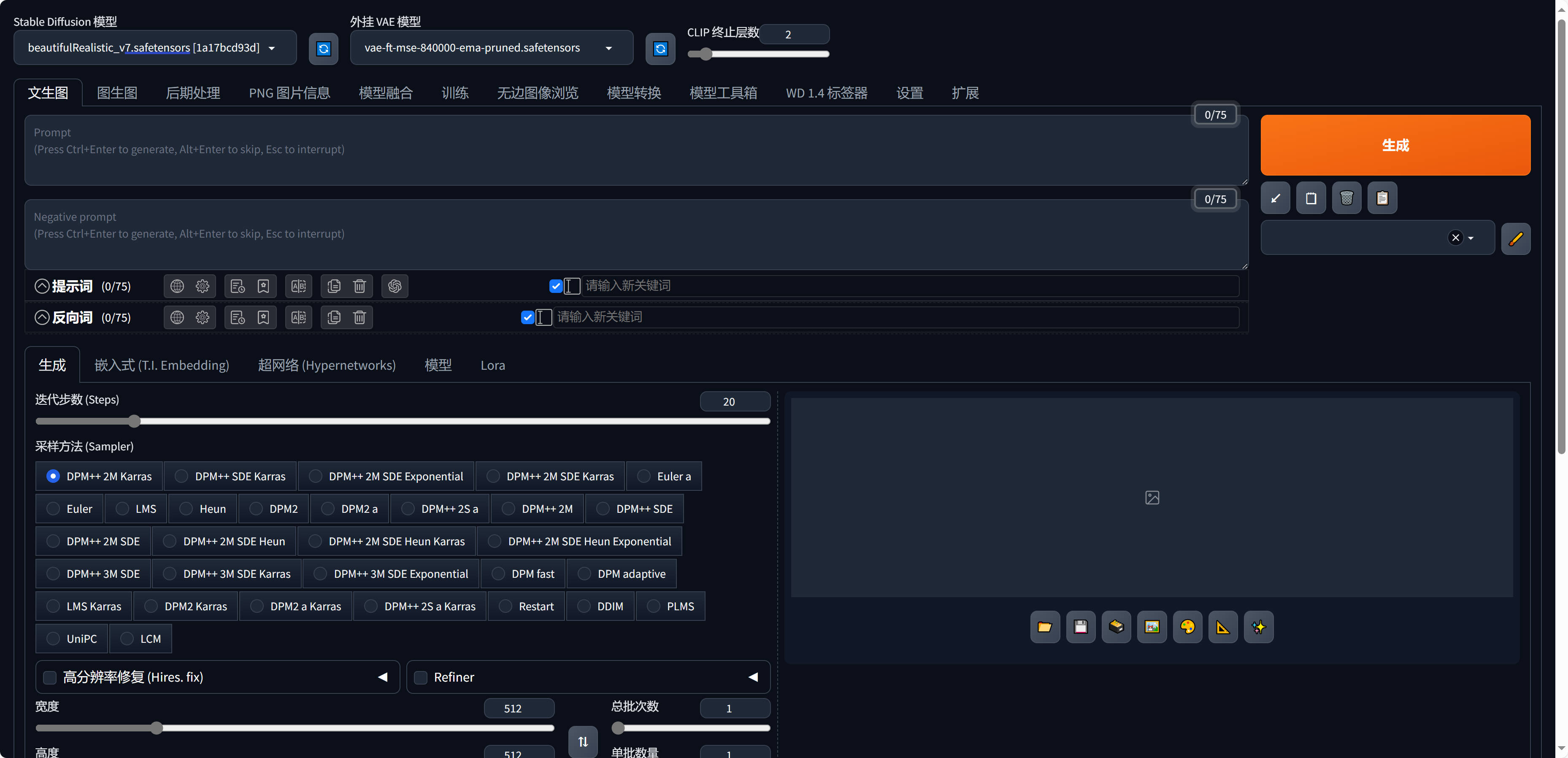
具体的使用教程请善用 google。
音频类工具
suno.ai
suno.ai 可以让你提供歌词,和对应的歌曲风格就可以生成质量很高的歌曲,我目前生成的 8 首里,有几首觉得还蛮好听的。
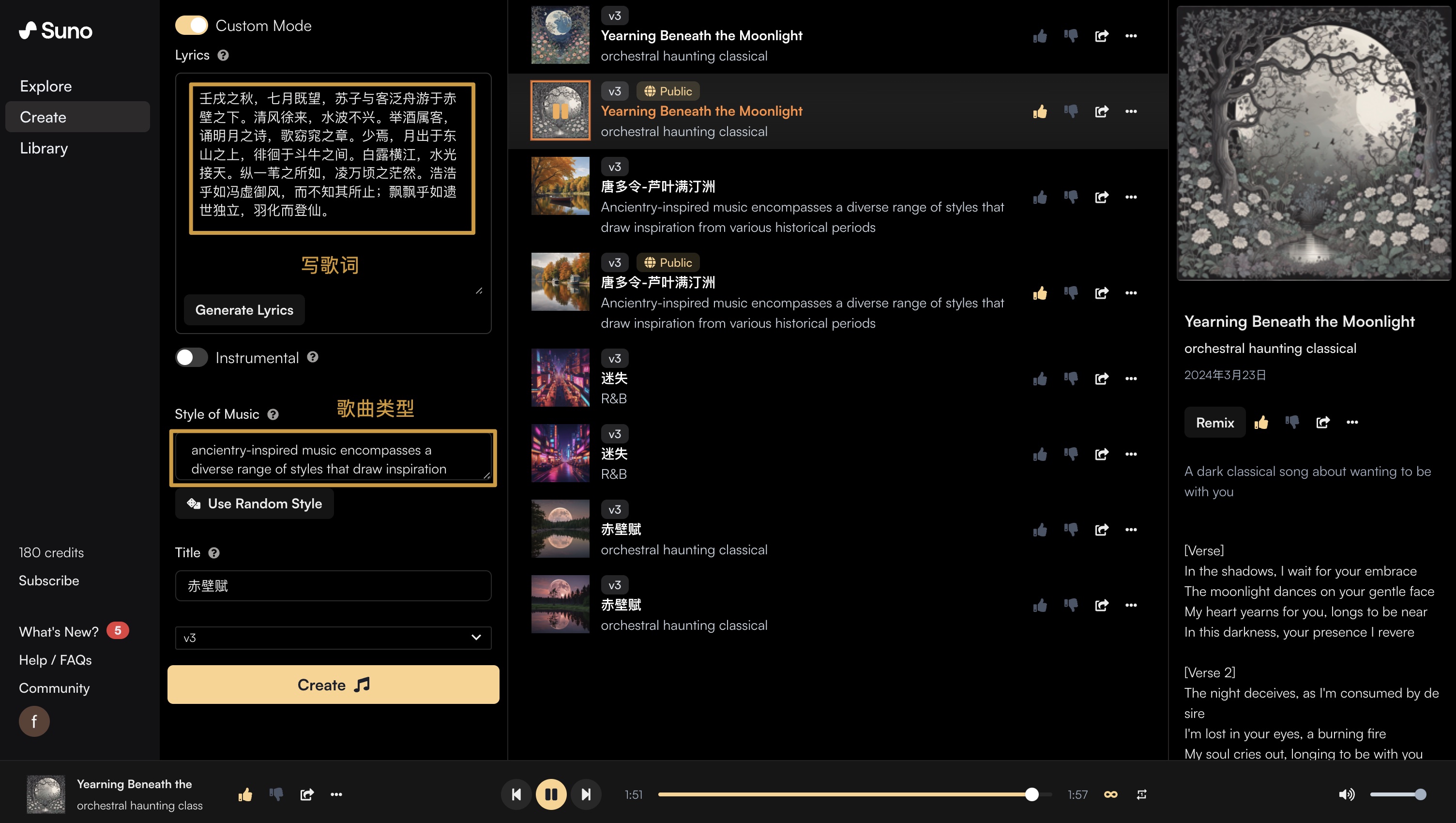
点击下面两条链接即可收听对应的 ai 歌曲:
So-VITS-SVC
这个项目跟 SD 类似的,都是使用 gradio 开发的一个工具,功能是推理声音,可以将你给定的音频替换为训练好的模型的声音。
步骤就是使用 UVR 这个软件来分离人声和伴奏,然后使用 So-VITS-SVC 替换声音为模型声音,当然 So-VITS-SVC 也可以训练声音模型,具体的步骤可以看 藏师傅的教程.
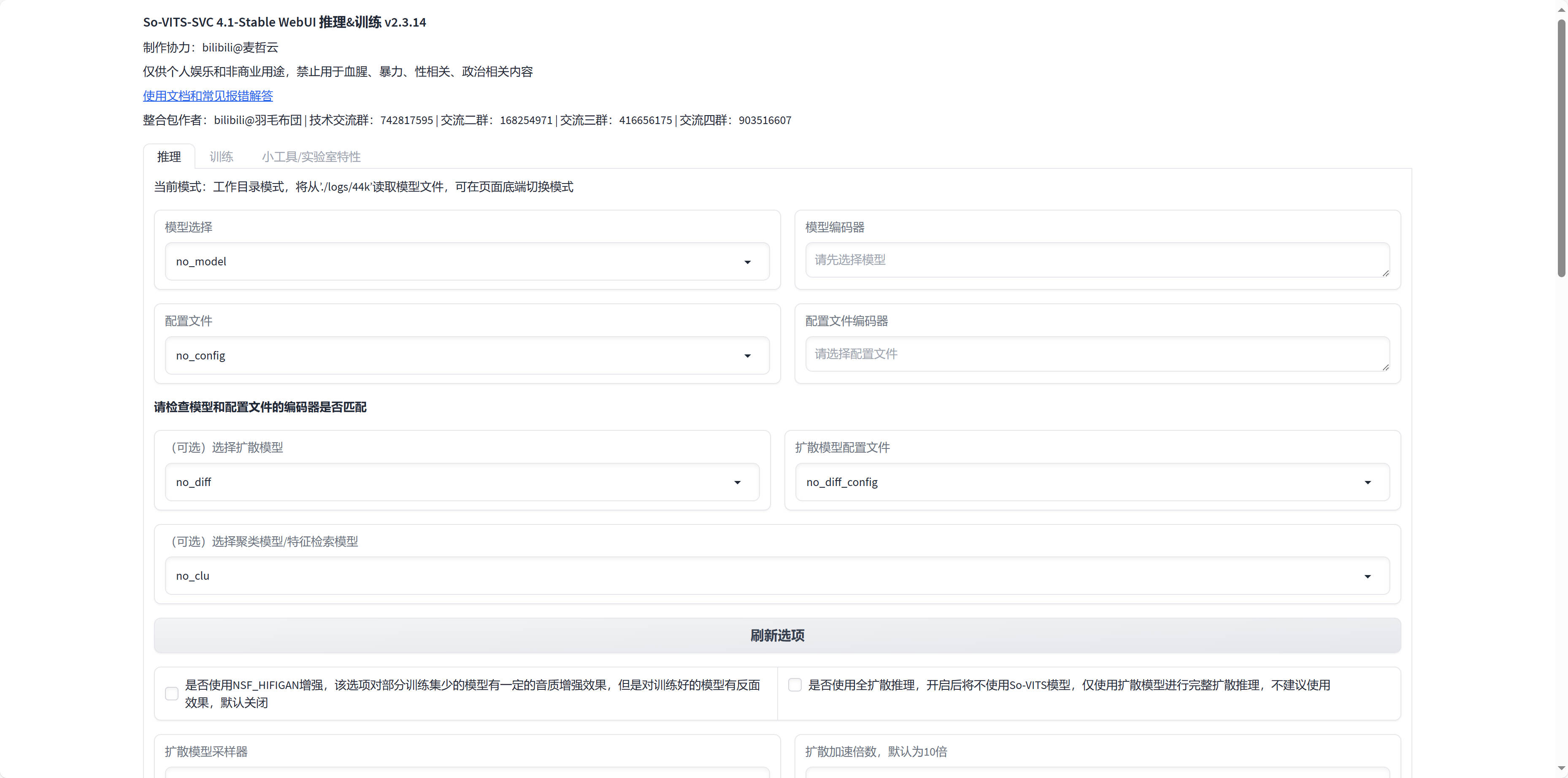
这里是我训练的孙燕姿唱的「摇篮谣」, 这个是原版的, 可以对比听下。
如果你想训练自己的声音为模型,需要一个几个小时的朗读声,然后使用 So-VITS-SVC 就可以训练一个模型,需要注意的是,需要你的电脑配置还不错。
所有的软件的下载链接(不包含孙燕姿声音模型) 提取码: 1026, 如遇过期,请左下角对话联系我.
其他工具
其他工具大概得分类有:写作类,办公类,设计类,编程类等, 做好付费准备,任何优秀的工具都值得我们付费(除非有免费版,哈哈哈哈哈哈哈)。